

How webscraping is Detected
Proxies have a lot of use cases which includes browsing, gaming, using them for scraping websites and so on. Browsing and gaming do not include a lot of challenges but the question here is have you ever used a proxy or set of proxies successfully without getting blocked by target websites? If the answer is “Yes” it’s great to hear, but 90% of the users have a “No” as their answer.
In this article, we will discuss how the proxy usage affects scraping, how websites detect proxies and the preventive measure one can take while using the proxies for scraping.
Let us begin with the basics, Web scraping is performed by web crawlers with the use of random IPs as bots to retrieve data and download large files from a target website, Multiple crawlers are used to get the data faster. But getting the data faster doesn’t mean you can abuse the website or the server it is hosted on. Yes, most of the crawlers are blocked due to the same reason.
Get this Ebook Guide : Content Curation with Web Scraping.
If a crawler sends a lot of requests per second and continuously downloads large files, a low featured hosting server will surely break down due to the number of requests sent on it or the load due to multiple crawlers. As it is always noticed that web crawlers affect the performance of the site on a very huge basis, there are websites which have implemented anti-scraping mechanisms which block the crawlers from accessing or retrieving any data from the website as they do not prefer providing access to their data to anyone. However there are handful of website owners who still allow them in order to improve user experience on the website.
Different websites use different mechanisms to identify crawlers on their websites. However, there are few commonly used techniques which anyone who thinks of scraping websites must have a look into.
The best way to identify if a website allows or denies scraping is by researching on the website to check if any anti-scraping mechanisms have been deployed. The simplest way is to check the presence of robots.txt file, if this file is present on the website, you can check for a code or a line added as below.
User-agent: * Disallow: /
This line prevents bots which are configured to respect robots.txt and hence scraping will not be done.
The authentic method of banning a web crawler or a web spider is by banning the IP address on which the bot is configured, however there are chances that the bot uses multiple IP addresses, hence the second and most widely used option is to ban the ID used by the bot while accessing the website so that any change in the IP doesn’t matter thereafter. The ban can be temporary or permanent which is completely dependent on the website owner, if it is temporary, the ban will last for not more than few hours. However, if it is reported that the site performance has deteriorated due to crawlers then a permanent ban is done.
There are a lot of possibilities that indicate that you are banned by the website while crawling, so when these errors appear the best way is to stop scraping the site.
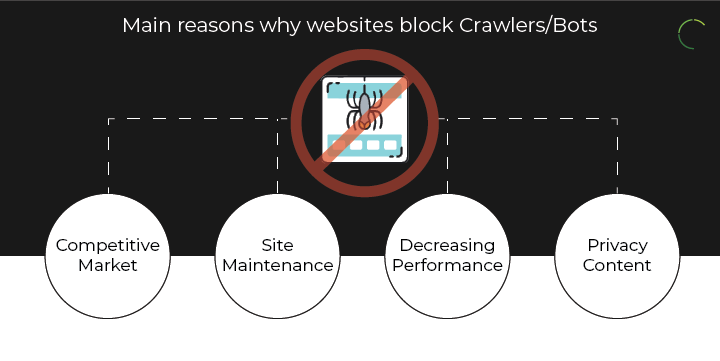
There are several reasons why a website blocks bots or deploys anti-scraping measures. They can be security, competition or just the performance of the website.
Let us know some of the common practices reasons.
1. Competitive Market:
Ecommerce websites which are popular among the public often want to stay connected with their regular customers, due to which they make sure that they do not provide the information of the offer they are running to their competitors. This sounds weird but they design the websites in such a way that incorrect information is garnished while the competitors themselves access the website. This can be customized using the network address but as it is quite complex the usage of this method is limited to some websites.
The best example is with the news websites. You access a news website and they provide information relevant to your location or the state you are checking it from. Similarly, some shopping websites display information depends on the browser or the device they are getting requests from.
2. Site Maintenance:
Websites normally block bots when they experience a high number of visitors even when the ideal number of visitors on their websites is very low. This is concluded when you check the bandwidth on the website on a regular basis. So if you were able to access a particular website and it is now blocked, the only conclusion here is that your IP or your network is blocked as the site owner has recognised you scraping data from their website. This is a common practice in scraping but blocking the IP address is not the only solution as there a whole lot of IP addresses from which you can still connect to the website.
The best practice is to keep the crawling for a larger period on a website and perform it slowly with a considerably large amount or a pool of IP addresses from different subnets.
3. Decreasing Performance:
Using Bots on websites deteriorates the performance of the site in a huge way. It is always referred that usage of a lot of automated system on a website always makes the performance poor. Small websites usually host the sites on basic or shared servers which has a very low capacity of handling request and when a large number of concurrent requests appear the performance goes down drastically.
Hence it is advised to keep a tracking of data you have scraped from a particular site and then schedule scraping periodically than sending requests at once. This will surely take a lot of time for you to yield the information you want but will look more human and avoid yourself from being blocked.
4. Privacy Content:
There are a lot of sites which are built in such a way that the information is available only for limited people., This can be money related or information related, but when these restrictions are set on the website it simply means that it is not only blocking automated access but even unwanted visitors as well. A very few sites are built this way as the process to develop this site is too complex and needs a lot of programming work. Hence accessing these sites from automated bots or crawlers can directly violate their terms of services leading to blocking or legal issues. Using a proxy you can still mask your location and access these sites which is an added advantage just in case you really need information from the target website.

Preventive Measures taken to avoid from being Banned
There are a very few sets of steps that can be used prevent the blocking of websites from a particular IP. However, these are based on how you use them and a small mistake in the performance can still get you blocked. Let us have a look at some measure to be taken to avoid blocking.
1. Do not Abuse the server of the target website:
There are a lot of instances where auto mechanisms have been used in such a way that certain amount of data has to be retrieved in a specific time which leads to multiple crawlers attacking the website at a given point of time which leads to bad performance of websites and hence bots are banned upon detection. The best way to prevent this is by adjusting the crawling speed to a normal level or to a level in which a human accesses links on the websites, this can retrieve the data for you and also avoid the bot of the IP from being banned, Always perform a trial once you adjust the speed to know if it is optimal for use. Fast crawling is a problem for you as well as the website owners and visitors.
2. Use of Rotating IPs or Proxies:
A lot of website scraping techniques use a single IP to perform all the crawling requests on multiple websites or the possibility of being using a single IP on multiple crawlers which access different pages at the same time. This easily allows the website owner to know that the IP used on the website is a crawler as the same IP is visiting multiple pages on the website at the same time. Using different IPs can make the work easy for you, it is not necessary that you have to use an ISPs IP, you can go for proxies or providers that allow setting up automated pool of IPs which change in certain period of time. The best way to disguise is by using different subnet or different range of IPs. If you are using a set of IPs for scraping always make sure that the IPs doesn’t look like below:
50.118.160.1 50.118.160.22 50.118.160.101 50.118.160.198
Using IPs from a single subnet will surely get you blocked as it is evident that the IPs are from a single provider and hence a single bot is using the IPs, always keep the subnets different from each other. The best practice is to keep the IP providers different from each other. As per recent research, it is better to avoid AWS IPs as most of the IPs are already banned.
Check also : Proxy for Web Scraping
3. Spoofing:
If you are knowledgeable in scraping then you know that bots use user-agent headers for representing themselves. Using the same agent for all the crawling on the same website can always lead to detection of bot and get you banned. The best way to avoid this is by creating a list of user-agents and using random agents for each request.
By doing this you can also do the scraping and the website will not find any suspicion in your usage which can avoid blocking 95 out of 100 times.
4. Avoid Honey Pot Traps:
Honey pot traps are links which are invisible to a normal user but can be detected by a bot or a spider. These links are deployed for the same purpose. When a bot with a specific IP crawls over all the links on a website and then follows links leading to honey pot traps, it is clear that it is not a normal user but a spider trying to retrieve data from a website.
This mechanism is not so simple as it requires a lot of programming knowledge and the deployment is very tricky. Hence it is not so commonly used by either bots or the website owners.
The best and most common practice that can be followed to avoid honey pots is by using different sets of IPs to crawl over all the links in the initial stage which does not trigger any warning to the website owner about any crawling activities. Also it is always good to keep monitoring the Honey.Pot file added in CSS or Javascript while performing the crawling process. These are not sure shot steps, but precautions to be taken, however researchers are still in process of finding a standard method to stay safe from being blocked by honey pots.
5. Crawling Pattern:
A browsing pattern can always let the website user know if the visitor is a bot or a human. Robots functions how they are programmed and for sure will follow the same things with crawling or retrieving data from websites as well which is common.
Some high end sites with a lot of graphics and lot of data deploy highly intelligent anti spider measures to prevent crawling on their websites. Accessing the same link multiple times or accessing multiple links at the same time with same IP will easily blow the cover for the bot. The best way to avoid this is by setting a pattern which will access randoms links on the page, use cursor movements which will make the bot look natural.
6. Robots.txt File:
If you know about the robots.txt file then you should also understand that it is not deployed to block the bots but to set rules how the bots are supposed to perform crawling and on what pages. A bot which is programmed to follow the rules set on robots.txt will by default follow these rules and retrieve data. This lets the website owner have their websites intact and the bots can perform their crawling without getting banned.
In some cases, you can still find robots.txt file being set to only allow Google bots to scrape data whereas all other bots are banned from extracting any data, but as this is decided by the website owner, there is nothing you can do to avoid this rule.
You should also note that when site owners do not find a way to stop crawling on their sites, they simply implement captchas or text message validations in place for all the links which will surely irritate any human or bot while accessing the links. However if your reason is legit, you can still proceed with the same.
Conclusion
We have discussed several practical reasons that lead to getting blocked from websites and similarly found measures to avoid getting blocked. But it is completely dependent on how you use the tools to scrape data, the best practice to avoid being blocked is hiring a pool of IPs from a proxy provider with different subnets and implementing them on your tool. Learn about the website and the intelligence tools they have deployed on their website before you begin your process. Good luck.!!
Try to check also this web scraping guide and Web scraping for business for more learnings.
Related Blogs
The Top 5 Guidelines for Scraping Amazon Safely
5 Web Scraping Lessons Every E-Commerce Data Scientist Must Know
An Ultimate guide to content curation with web scraping in 2019
The Ultimate Guide to Proxies for Web Scraping
How Web Scraping Can Help You Get Ahead in Your Market?
Post Quick Links
Jump straight to the section of the post you want to read:


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
Proxy Servers Explained
Proxy servers are essential to ensuring data protection, privacy and better connectivity. Here's your ultimate guide to proxy servers by Limeproxies
How Plugins can Interfere with your Online Security?
Internet, a system of networks which connects computer devices around the globe, which was developed to simplify the interchange of information and opinions.