

Data extraction from websites is an increasing necessity especially when there is a need for price monitoring, business analytics, or news aggregation. Copying and pasting data line by line would be an option if it were in the dark ages, but with the vast development in technology, better ways exist for data extraction. Since most of the data available on the web exist in an unstructured format, extracting and recording data is not possible and that is where web scraping comes in. web scraping allows you to convert the unstructured format of data into a useable format so you can easily get the data you need. And so in this article, you would be taught how to perform anonymous web scraping using python.
Post Quick Links
Jump straight to the section of the post you want to read:
Methods of Extracting Data from the Web
Different methods exist for the extraction of data from the web and are utilized as users deem fit. Two methods, however, stand out and are more popular than the rest.
Interesting Read : Top 10 Web Scraping Techniques
The first method and the most desirable of all is web extraction by the use of an Application Programming Interface (API). This method is the choicest because it gives you direct access to structured data from the provider and you can extract in this format without any difficulty.
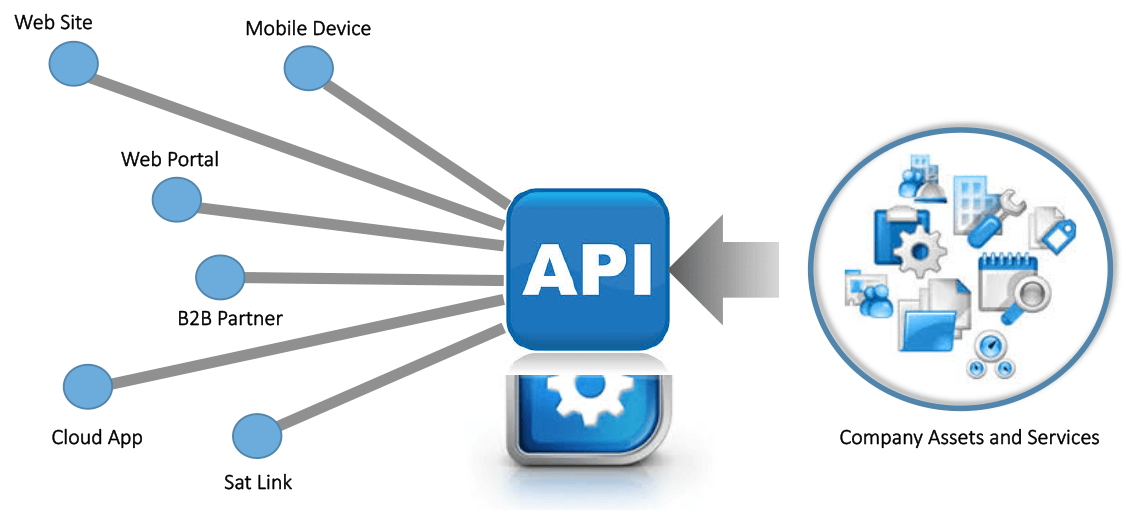
The use of API as a method to extract data has its own shortcomings which make it a choice that is not feasible. One of the reasons it can’t be used is that providers rarely give access to structured data from their websites. And even if they do not have an issue with it, the technical knowledge is not available to everyone.
Being faced with such problems to the smooth use of API, web scraping becomes the only option that is feasible to get data from the web. Web scraping is a very useful and effective and indispensable technique when it comes to extracting data from the web.
Contrary to popular belief, anonymous web scraping using python is completely legal. The only exception to this is when it is done on a website that has blocked crawlers using robots.txt or has a Terms of Service page that clearly states that web scraping isn’t allowed.
What Is Web Scraping?
Web scraping is a technique that allows you to extract data from the web. It allows you to convert the unstructured data (HTML format) on the web that you cannot have access to structured data (like a database or spreadsheet).
When Is Web Scraping Required?
Since the use of an API is not feasible in extracting data from the web, web scraping is the only solution and the best to extract large amounts of data. It has been around for a long time and has seen improvements that have made it more reliable.
In business, an analysis of key trends is important in making decisions. There is a lot of information out there to guide informed decisions and it is very unwise to make blind choices. Anonymous web scraping using python will provide you with all the required data for complete analysis so that whatever decisions you make will be an informed one.
Interesting Read : Effective web scraping tips and tricks for efficient business activities in 2020
Web scraping also helps you monitor your brand and help your online presence a success. As good as positive feedbacks and comments are for your reputation and popularity, negative mentions on social media and other websites like Facebook, Twitter, or Google Business can ruin your brand name and reputation. This is bad for business and will reduce your revenues in the long run. So anonymous web scraping with python can help you keep a close check on all your mentions be it comments or tags so you can more effectively manage your brand.
Other applications of web scraping include finding listings for a real website, in powering artificial intelligence experiments which may involve the use of many keyword linked images, in price monitoring of competitors on different e-commerce websites and tracking the stock market in real-time.
Why Use Python for Anonymous Web Scraping?
Python is a suitable language for web scraping because the programming language is easy to learn and work with. The syntax is similar to English and the core concepts are not difficult to understand. This makes it most suitable for efficient web scraping even by someone who has no past experience with programming.
Interesting Read : 5 Best languages for web scraping
Another reason to use python in web scraping is that its ecosystem is elaborate and supportive when it comes to web scraping. While other programming languages have libraries that help with web scraping, python’s libraries have the most advanced tools and features for web scraping.
Python is compile free as it is an interpreted scripted language. This means that changes are applied immediately you run the application you have written the next time. So mistakes are easily fixed and web scraping is faster when done with python.
Which Libraries Can Be Utilized For Web Scraping With Python?
As already stated, one of the advantages of using python for web scraping is access to some of the most advanced tools and features in python’s library. These include:
Scrapy
Scrapy is a comprehensive framework that is for web scraping with python. It allows you to download data in the unstructured HTML format from websites and then storing them in the form that you want. While it is a very efficient tool and takes up very little CPU storage space, it is hard to install and maybe too much to handle simple scraping tasks.
urllib
urllib is effective for fetching URLs. It defines the functions and classes that define URL actions.
Beautifulsoup (BS4)
Beautifulsoup is a parser and it allows you to extract information from a webpage. You can extract lists, tables, and paragraphs. It is one of the most popular and easiest to use python tools for web scraping.
LXML
LXML is a parsing library that effectively parses both HTML and XML pages. It is one of the best parsers that exist today but its complex documentation makes it difficult to use by beginners.
Other libraries that can be used for web scraping with python include Mechanize, Scrapemark, Selenium, and Requests.
HTML Tags You Need To Know For Web Scraping With Python
Web scraping with python doesn’t need the expertise of a python or HTML expert. You do however need to e familiar with useful HTML tags before you get started. A basic HTML syntax looks like this:
<!DOCTYPE html>
<html>
<body>
<h1>My First Heading</h1>
<p>My first paragraph.</p>
</body>
</html>
Here is a guide to understanding these basic HTML tags:
<!DOCTYPE html> : all HTML documents begin with this introduction so you can identify it easily.
The HTML document is contained between <html> and </html>
The visible part of the HTNL document is between <body> and </body>
HTML headings are defined using the <h1> to <h6> tags in decreasing sizes
HTML paragraphs are indicated using the <p> tag
Other HTML tags that you would need to know to for good web scraping using python are:
The <a> tag is used for links.
HTML lists begin with <ul> (unordered) and <ol> (ordered). Ordered lists are either numbered or alphabetical, while unordered lists are bulleted.
HTML tables are defined with the use of <Table>, row is defined using <tr>, and rows are divided into data using <td>
Steps in Web Scraping Using Python
In this article, we will make use of two python libraries to scrape reviews from Yelp. The libraries are Beautifulsoup in bs4 and request in urllib. These two libraries are popularly used to build a web crawler using python.
Step 1: Import Python Libraries
In web scraping using BeautifulSoup and request, the first step is to import these libraries in python so as to make use of their functions.
#import packages
From bs4 import beautifulsoup
Import urllib.request
Step 2: Extract the HTML Data from Web Page
The data to be extracted as already stated are reviews from yelp, so the reviews will first have to be extracted from here and the url saved in a variable called url. Then the content on the webpage is accessed and the HTML saved in “ourUrl” by using urlopen() function in request.
#the targeted URL
url = ‘https://www.yelp.com/biz/milk-and-cream-ceraal-bar-new-york?osq=ice+cream’
#use request to open the URL
ourUrl=urllib.request.urlopen(url)
Then we parse the page by applying BeautifulSoup
#create a beautifulsoup object, which represents the document as a nested data structure
#parse the page
Soup=BeautifulSoup (ourUrl, ‘html.parser’ )
Now that we have the raw HTML for this website which is the ‘’soup”, we could utilize a function called prettify() to clean the raw data before printing so we can see the structure of HTML nested in the ‘’soup”.
#to see what is inside the soup
Print (soup.prettify () )
<DOCTYPE HTML>
<! – [if lt Ie 7 ]> <html xmlns:fb=http://www.facebook.com/2008/fbml” class=”ie6 ie ltie9 ltie8 no-js” lang=”en”> <! [endif]->
<! – [if IE 7 ]> <html xmlns:fb=http://www.facebook.com/2008/fbml” class=”ie7 ie ltie9 ltie8 no-js” lang=”en”> <![endif]->
<! – [if IE 8 ]> <html xmlns:fb=”http://www.facebook.com/2008/fbml” class=”ie8 ie ltie9 no-js” lang-“en”> <![endif]->
<! – [if IE 9 ]> <html xmlns:fb=”http://www.facebook.com/2008/fbml” class=”ie9 ie no-js lang=”en”> <![endif]->
<! – [if (gt IE 9) | ! (IE) ] ><!->
<html class=”no-js” lang=”en” xmlns:fb=”http://www.facebook.com/2008/fbml”>
<! -<! [endif]->
<head>
<script>
(function() {
Var main = null:
Var main=function () {window. Onerror=function(k, a, c, I, f) {var j=(document.getElementsByTagName(“html”) [0]. getAttribute(“webdribver”) =”true” ||navigator. UserA
Step 3: Locate and Scrape the Reviews
The next step is to find the HTML reviews on the web page, extract them and store them. Each data in HTML format has a HTML “ID”. This will be inspected on the web page.
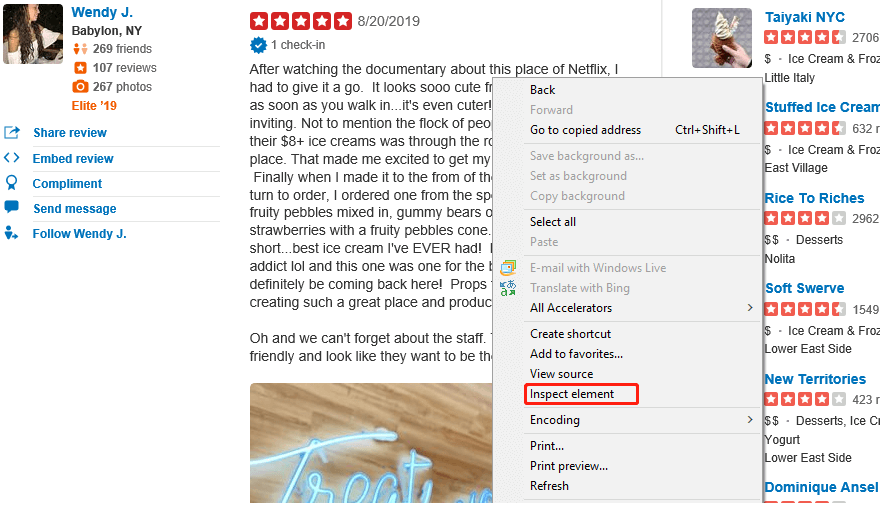
After clicking the “inspect element”, the HTML of the reviews will be displayed.
The reviews are located under the tag called “p” in this case. So we will first find the parent node of the reviews using the find_all() function. Then we will locate all elements carrying the tag “p” under the parent node in a loop. After finding all “p” elements, they will be stored in an empty list “review”.
Review=[] #create an empty list to store reviews
For I in soup.find_all(‘div’, {‘class’ :’review-content’}) :
Per_review=i.find(‘p’) # extract review
Print(per_review)
Review.append(per_review) #append review
<p lang=”en”>After watching the documentary about this place of Netflix, I had to give it a go. It looks sooo cute from the outside and as soon as you walk in…it’s even cuter! It’s nice, bright, and inviting. Not to mention the flock of people waiting to get their $8+ ice creams was thorough the roof. People love this place. That made me excited to get my hands on one. Finally, when I made it to the front of the line and it was my turn to order, I ordered one from the specials menu that has fruity pebbles mixed in, gummy bears on top and strawberries with a fruity pebbles cone. Long story short…best ice cream I’ve ever had! I’m an ice cream addict lol and this one was for the books. I will definitely be coming back here! Props to the owner for creating such a great place and product. <br/><br/>Oh and we can’t forget about the staff, they are all very friendly and look like they want to be there. I love that!</p>
<p lang=”en”>Fav dessert spot when my friend and I spend the day in the city. The “specials” are delicious and there are very satisfying combinations..my fav being the chocolate cocoa crunch. The ambiance is nice as well, bright lighting and cute visuals. <br/><br/>Just make sure to not sit in the seats right next to the register because the a/c is way too high and melts the ice cream in your hand all over the place. </p>
<p lang=”en”>TLDR: I’m in love with this place! Every flavor of ice cream is so true to taste and I firmly believe you have to come here at least once for the gram ☺ you can’t go wrong with any flavor, so I’ll be back to sample the rest of the menu
After getting all the reviews from that page, we will now see the number of reviews that have been extracted.

Step 4: Clean the Reviews
There still some unnecessary texts in the review that need to be cleaned. Examples are Texts like “<p lang=’en’>” at the beginning of each review, “<br/”in the middle of the reviews, and “</p>” at the end of the reviews.
“<br/>” represents a single break line. Break lines in reviews are not needed in reviews so they need to be deleted. The other texts at the beginning and end of the HTML texts also need to be deleted.
#basic clean
New_review=[] # create an empty list to store new reviews
for each in review:
new_each=str (each) . replace(‘ <br/>’,’’) #remove <br/> with empty, which means delete
new_each=new_each[13:-4] #remove first 13 strings and last 4 strings, which
#are <p lang=’ en’ > and </p>
Print (new_each)
New_review.append(new_each)
After watching the documentary about this place of Netflix, I had to give it a go. It looks sooo cute from the outside and as soon as you walk in…it’s even cuter! It’s nice, bright, and inviting. Not to mention the flock of people waiting to get their $8+ ice creams was thorough the roof. People love this place. That made me excited to get my hands on one. Finally, when I made it to the front of the line and it was my turn to order, I ordered one from the specials menu that has fruity pebbles mixed in, gummy bears on top and strawberries with a fruity pebbles cone. Long story short…best ice cream I’ve ever had! I’m an ice cream addict lol and this one was for the books. I will definitely be coming back here! Props to the owner for creating such a great place and product, oh and we can’t forget about the staff, they are all very friendly and look like they want to be there. I love that!
Fav dessert spot when my friend and I spend the day in the city. The “specials” are delicious and there are very satisfying combinations..my fav being the chocolate cocoa crunch. The ambiance is nice as well, bright lighting and cute visuals. Just make sure to not sit in the seats right next to the register because the a/c is way too high and melts the ice cream in your hand all over the place.
TLDR: I’m in love with this place! Every flavor of ice cream is so true to taste and I firmly believe you have to come here at least once for the gram ☺ you can’t go wrong with any flavor, so I’ll be back to sample the rest of the menu.


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
Tips To Become A Great IT Security Manager
IT security or Security of Information Technology – it is a very crucial concern nowadays. With the increase in technological development, there is an increase in the number of confidential documents with IT companies’ and also there is an increase in online thefts.
Top 10 Machine Learning Algorithms that will make work simple
It is defined as a scientific study of statistical models, computer systems and algorithms. Learn more about our web scraping proxy service.