

Google introduced the first captcha as distorted text which is nonetheless readable by humans. As times went by google introduced reCaptcha with the use of images like traffic lights, fire hydrants, crosswalks, stairs, and chimneys. They shut down ReCaptcha V1 and introduced ReCaptcha V2 and V3 in 2018. The various types of ReCaptcha have their own specific functions which are:
- ReCaptcha V2 asks for the user to click on a checkbox.
- The invisible form of ReCaptcha V2 is prompted when there is a suspicious traffic activity on a website. The site owner is alerted and then chooses how to handle the situation.
- ReCaptcha V3 is an enhanced invincible ReCaptcha. It analyzes the interaction between the user and the browser and device fingerprints, and then sends the score of these to the site owner.
It is up to the site owner to either block, cloak, ask for additional authentication, or blacklist the IP completely when deciding how to handle suspicious activities on the website. So what then does ReCaptcha do? Apart from solving pictures, ReCaptcha adds cookies and collects device fingerprints (browser and device profile).
Advanced fingerprints allow for mouse movement and audio signals captured from the device to be analyzed. What then should be done to solve and prevent ReCaptcha? Using a real IP from a good proxy server is a great first step. Most websites will check the integrity of your IP and a real IP bypasses this step.
Post Quick Links
Jump straight to the section of the post you want to read:
PREVENTING RECAPTCHA
A real IP is also known as a residential IP and is ideal to be used if you want to bypass ReCaptcha. Residential IPs could either be rotating or static. Rotating IPs belong to real users and they are rotated every time a certain IP is no longer idle. A static IP, on the other hand, is permanent and is issued by ISP, meant for commercial use. Static IPs are similar to the rotating type only that they are only used by the customer who made the purchase and so do not rotate. If you would be visiting some social media and ticketing sites, it is better to use a static IP as the site checks for the persistence of the account IP.
Many target websites make use of ReCaptcha on sensitive pages like registration pages or when posting information. Another way of preventing Recaptcha would be with the waterfall solution. You begin by sending requests using the data center IPs and then route it to a residential IP while crawling sensitive pages. The waterfall method promises a high success rate and saves you cost too. An example of this process would be to send requests through the data center network. If the request sending fails, then it is sent through the residential network. if this also fails, it would automatically be routed through the mobile network.
Another way to use the waterfall method is by routing requests through different geo-locations. It is useful when scraping an e-commerce website for product pages and ReCaptcha comes up. Changing the IP from one location to another in a different location can work to overcome ReCaptcha.
Interesting Read : How to monitor competitor prices in e-commerce?
Now we will discuss the process of implementing a URL rule to rotate between networks. It is important that each proxy port in the LPM be allocated a different network type. Once this is done and the ports ready, you need to create a rule that is triggered when a chosen URL is launched, switching the IP to a residential one. From the action drop-down list, select ‘retry with new proxy port’ and it will initiate waterfall routing. In the retry section with a different port drop-down list, select the port you wish to use with the residential zone.
What some simple target sites do is just to analyze the browser profile like its header and the kick up an invisible ReCaptcha. To prevent and solve this ReCaptcha, send a real browser header and change it for each request. You can set the browser header values under the headers tab in the settings of each proxy port. If you want, you can manually add the header values like cookies, accept-language and the likes by typing the name and value according to your target website’s headers.
If you are working with the proxy manager API, you can set the requires headers by creating a new proxy through sending a POST request or by updating the proxy port via PUT request while sending the JSON configuration file of the port. The relevant field of the configuration file is the header array which contains names and values of the header field. Take for instance, for a particular site, you will add ‘cookie’ under the name field and under the value field is the string for the cookie itself. With this, you can include similar or different cookie values for each request while getting different cookie values from cookie databases that are relevant to your target website.
The same thing can be done in Puppeteer or Selenium by adding the browser headers in your code. A good proxy manipulation is to resolve the DNS on the peer side rather than at the super proxy side. DNS resolve translates from an IP to a URL and the advantage of resolving DNS at the super proxy side is a resultant faster request. Resolving at the peer side results in greater anonymity especially when you use a bot or crawler. You can resolve DNS by going to the request speed tab in proxy manager and select remote resolve by the peer in the DNS lookup field.
Some target websites that make use of ReCaptcha V3 or make use of sophisticated analyzing features can monitor fingerprints like the mouse movement, webRTC rendering, audio signal analysis and much more. Audio signal analysis can be overcome by adding an audio file/signal to your request. Use a text to speech tool to crate the audio you need and then include it in your request.
Interesting Read : Top 10 Web Scraping Techniques
When the request has a populating audio part as part of it, you will notice that ReCaptcha V3 is absent. You can also populate other fingerprint parameters as part of a multi-login browser profile and it includes canvas, static audio noise, WebGL, etc. if you want to overcome ReCaptcha while crawling and not interrupt the process, first start by retrying using a new IP when ReCaptcha comes up. You can do this in the rules tab of the proxy manager by creating a new rule. Set the trigger to ‘HTML body element’ and for the string to be scanned, type in whatever word that appears in the browser console. After this, select ‘retry with new IP’ and the number of retries you would like and then test the rule.
Another option of solving the captcha is to actually solve it with the use of a third-party captcha solver such as 2captcha and anti-captcha. These two captcha solvers make use of real people who solve the captcha problems manually and send back the results to you after which you can proceed. The use of captcha solving services is not a very convenient option because you will have to detect the presence of captcha and then implement a complex API with which to send the solving request. The major issue while using these services is the response time as it takes an average of 40 to 60 seconds for the captcha to be solved and sent back to you.
THINGS TO KNOW ABOUT BYPASSING CAPTCHA FOR WEB SCRAPING
Captchas are annoying for most web users and you must have come across some while trying to access some pages of a website. They are those not so easy to read characters you are asked to enter into a text box. It is more difficult to deal with when using a web scraping bots for web scraping and so to better bypass this problem while scraping, you need to learn about captcha properly.
1 . UNDERSTANDING CAPTCHA
CAPTCHA is an acronym that stands for Completely Automated Public Turin test to tell Computers and Humans Apart. It is a test used in computing to tell robots and humans apart and is used across the internet. You will come across it either when making purchases online or when logging into a website and in some other situations too.
The aim of captcha is to ask questions and give challenges that computers are not able to deal with so as to distinguish bots from human users. It comes as a distorted string of characters ranging from numbers to alphabets. Even though it looks distorted, humans can make out the characters easily but it is a big issue for computers and that is why it works. Even if you are making use of a highly sophisticated automated system that can scan a picture of printed text and read the words on it, there will still be some difficulty ion reading it if the words are distorted or obscured too much.
TYPES OF CAPTCHA
There are various types of captchas and the common and most likely encountered ones are text-based captcha, image-based captcha, and audio based captcha.
Text-based captcha tests usually come in two parts. The first is a sequence of randomly generated characters (numbers and/or letters) that appear distorted and also a text box. This test involves typing the correct characters into the text box to prove you are human.
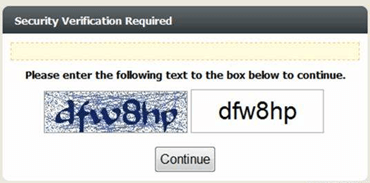
Some bots can equally pass this test and so to increase the difficulty of text-based tests, there is also a mathematical captcha. This is a basic math problem everyone can solve with easy to read numbers displayed with 3D effect.
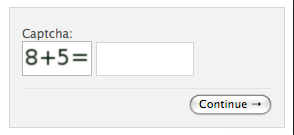
Image-based captcha is another type that makes use of images of animals, people, landscapes, or random objects instead of texts in order to confirm the user is a human and not a bot. to pass the test, users are required to select the right images that they are asked to identify or complete an image with the missing piece by dragging a block onto the incomplete image.

And now to audio-based captchas. This test makes use of random words or numbers from recordings in a combined form and adds a bit of noise to the sound. To prove that you are human, you are required to enter the words or numbers in the audio. This type of captcha is the most difficult to deal with as compared to text-based or image-based when web scraping.
HOW TO DEAL WITH CAPTCHA DURING WEB SCRAPING
The internet is a place to get lots of services and make purchases and so it has become very important that security measures be put up. The use of captchas in websites is to ensure that where human interaction is very important, human users are the ones being dealt with. Examples of such situations are when logging into a website and when paying for services and goods on the internet.
Captcha also prevents bots and spammers from extracting information from a website without permission. It prevents illegal behaviors and spam from taking over a website. Once a bot is detected the IP gets banned and you no longer have access to the site. To get around this problem therefore, you need to scrap with a proxy so that you can remain anonymous and have continuous access.
Interesting Read : Step By Step Complete Guide to Web Scraping With R
During web scraping, it is essential to deal with captcha because they can break down your crawlers if they show up. The best way to handle captcha is by avoiding it and there are some tips to help you avoid it.
Acting like a human even if you are using bots is a good way to prevent the appearance of captcha. This being noted, you should try to scrape a website moderately and never too much. Some captcha, however, appears on the login page and cannot be avoided. You can manually solve such captchas using octoparse.
If you are a web scraper who codes your own crawler, there are captcha solvers that you can integrate into your codes for the web scraper. Examples are Bypass CAPTCHA and Death by CAPTCHA. These two services allow you to connect via API and solve the CAPTCHA automatically while scraping is going on. The good thing about these CAPTCHA solving tools is that they can solve both captcha and ReCaptcha.
EXTENSIONS FOR WEB BROWSERS THAT CAN BYPASS AND SOLVE CAPTCHA
CAPTCHAs are meant to be a problem for computers only but easy to read by humans. This is not always the case as even people with good vision find it difficult sometimes to read them. Some types of captcha can be very annoying like google recaptcha. Here you don’t just solve one puzzle but sometimes you are required to solve about four puzzles back to back. Getting anyone wrong will have you keep going until you get them all correct and it can be very annoying.
In dealing with captcha, you can use a browser extension that solves it for you and saves you from the stress of doing it yourself. This will be particularly useful for those who have a hard time getting captchas right as it will save you time and takes the stress away.
1 . ANTICAPTCHA
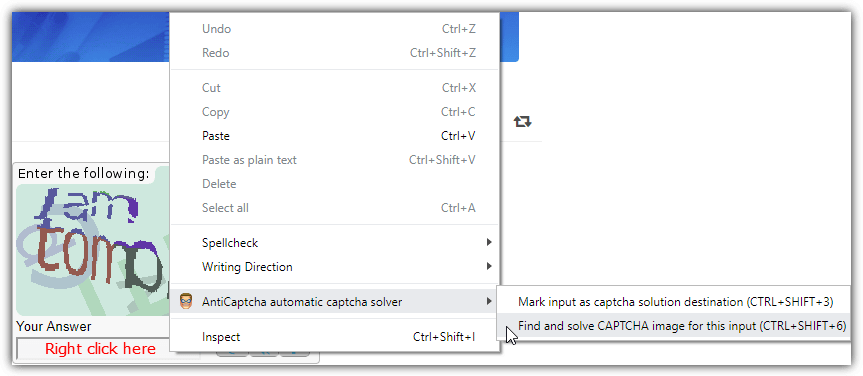
AntiCaptcha is a popular and highly recommended CAPTCHA solving service. This extension is available for use on chrome and firefox browsers and it is a paid service. Anticaptcha can automatically solve google ReCaptcha, fun captcha and also geetest once the page containing them is opened. For other regular types of captchas, you will need to right-click on the text box and select “find and solve captcha image for this input” or use the short cut Ctrl+Shift+6.
Solving captchas takes between 5 to 20 seconds on average and ReCaptchas take as long as 30 to 60 seconds on average.
2. BUSTER: CAPTCHA SOLVER FOR HUMANS
Buster is an open-source and a free-to-use extension that solves your captchas without any subscriptions. It can solve the audio kind of captchas by using speech recognition. Its drawback however is that it can only be used to solve Google’s ReCaptcha but since that is a very popular form of captcha, you will most likely find it handy for all your captcha solving needs. The extension is compatible for use with chrome, firefox, and opera browsers.
Interesting Read : Top 10 Web Scraping Techniques
Using Buster Captcha Solver is very easy and requires only a few mouse clicks to begin the ReCaptcha solving process but first, you will have to install the extension. Once a ReCaptcha pops up, you click on “I’m not a robot” to give you access to the challenge window. A green and orange icon will appear at the bottom and clicking on it will open the voice challenge window and allow Buster to begin solving it. Buster solves at a pretty fast speed and everything is usually completed under 30 seconds.
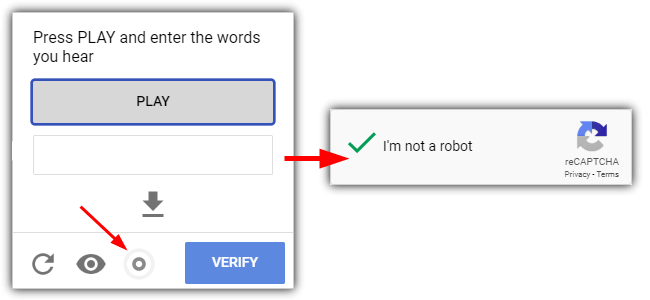
While Buster is solving, you will see a circular icon in the window. This icon will complete if Buster solves the challenge but if it fails, just get a new challenge by clicking on the far left icon.
3. RUMOLA
Rumola captcha solver works for captchas where you will need to type in words, numbers, or solve math problems. It can’t solve Google Recaptchas or image-based captchas and this is its limitation. Rumola can automatically search for captchas once a page is visited and you can turn off this option if you wish from the extension menu of your browser.
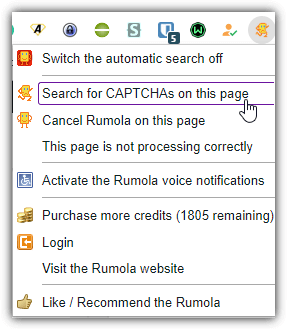
When a captcha is detected on a page, Rumola will overlay a small icon on the image and text box for answers. What you have to do is double click inside the empty text box and Rumola will take over as it animates the icons and solves the captcha. If the captcha isn’t detected, type into the text box or try “search for captchas on this page” from the extension menu.
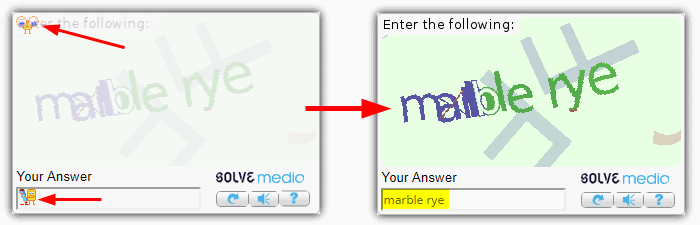
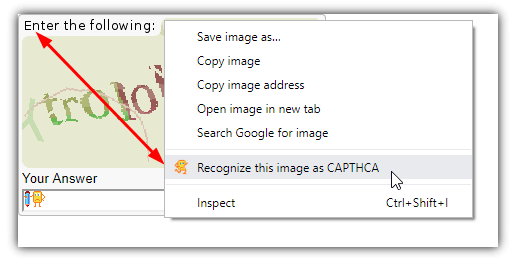
If nothing is still detected after searching the page, right-click on the image and select “recognize this image as captcha”. If the little icon that pops up doesn’t become animated, right-click on the answer text box and select “use this field to enter Captcha”. One out of all the stated options will get your captcha recognized and solved at a speed of only about 5 to 10seconds.
Rumola is a paid captcha solving service and installing for the first time gives you 5 free credits that you can use for testing.
4. RECAPTCHA SOLVER
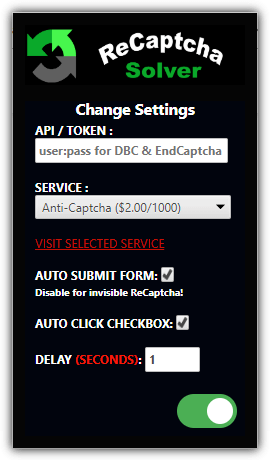
This is a third party extension service that is not owned by any specific captcha solving company. Before using this extension, you’ll need to be signed up and have purchased credits from either DeathByCaptcha, 2captcha, ImageTypers, Anti-Captcha, BestCaptchaSolver, or EndCaptcha. After the purchase, you can select your captcha service from the drop-down menu ad to enter either its API key or username and password.
CONCLUSION
Recaptcha is a problem for many internet users especially during web scraping as the crawlers can’t read the characters and pass the tests on their own. This blocks the whole scraping process and prevents then extraction of the necessary information you need. Captchas are not only a nuisance to bots but are also a problem to real human users with good vision and it can get annoying. That is why there is a great need to try and prevent the occurrence of captchas and solve them more effectively as they come.
Limeproxies offer you IPs from various locations that are secure and have fast internet speeds. To scrape more efficiently, you need a good proxy service to prevent your IP from being banned, and so that you can get good information that may be location-specific. Captchas are a roadblock to efficient data extraction and that is why it is important that they are prevented and solved as soon as they pop up.


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
What is a Sneaker Bot?
The next limited edition sale, you have more chances of getting that shoe pair. Know what is a Sneaker Bot by Limeproxies
What is SOCKS5? Do You Need It?
The online world is not safe, but what you do online can be safe. Know What is SOCKS5 and why Do You Need It by Limeproxies